Come risolvere l'errore 500 Internal Server su Character.AI
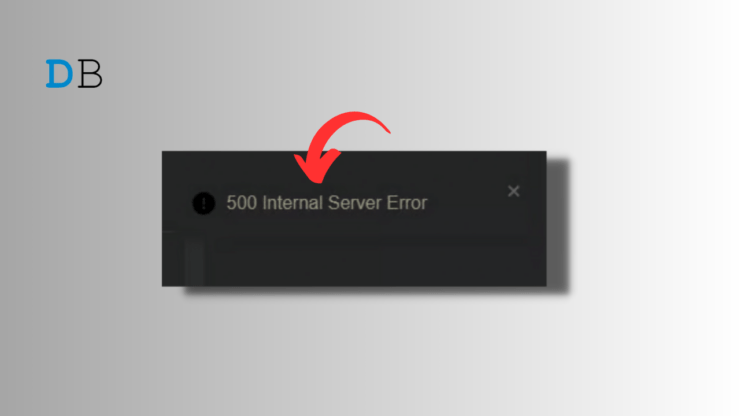
Se stai vedendo un errore 500 (Internal Server Error) su Character.AI, non sei solo. Questa guida passo passo in italiano ti accompagna dalle verifiche più semplici fino alle azioni rivolte a sviluppatori, SRE e supporto tecnico, con checklist, runbook d’emergenza e casi di test per assicurare un ripristino efficace.
Cos’è l’errore 500 e perché si verifica
Un errore 500 è una risposta generica del server che indica che qualcosa è andato storto sul lato del servizio. Non fornisce dettagli precisi: può coprire crash dell’applicazione, eccezioni non gestite, timeout su dipendenze esterne, errori di configurazione o picchi di carico.
Definizione rapida: 500 Internal Server Error — il server ha incontrato una condizione inaspettata che gli ha impedito di completare la richiesta.
Differenza rapida rispetto al 404: il 404 indica che la risorsa non è stata trovata (problema del client/URL); il 500 indica problemi interni del servizio.
Note importante: spesso gli errori 500 sono residui di problemi lato server, ma possono essere innescati anche da condizioni di rete, perdita di pacchetti o proxy intermedi. Verificheremo entrambe le direzioni.
Controlli rapidi per utenti (prima di ogni altra cosa)
- Aspetta 30–60 minuti e riprova. I riavvii o gli interventi automatici del servizio risolvono molti casi.
- Ricarica la pagina (Ctrl/⌘+R). A volte la richiesta precedente è scaduta.
- Prova con un browser diverso o dalla modalità privata per escludere estensioni.
- Verifica lo stato del servizio sui canali ufficiali e community.
Modi per correggere l’errore 500 su Character.AI
Character.AI può avere interruzioni, code o manutenzioni programmate. Ecco i passi ordinati dal più semplice al più tecnico.
1. Aspetta e riprova
Se il problema è lato server, il team potrebbe già star lavorando a una correzione. Aspetta almeno 30 minuti prima di eseguire altre operazioni. Durante picchi di traffico o deploy, il tempo di risoluzione può variare.
Importante: evita ripetute richieste automatiche ad alta frequenza (retry storm) che possono peggiorare la situazione.
2. Cancella la cache e i cookie del sito
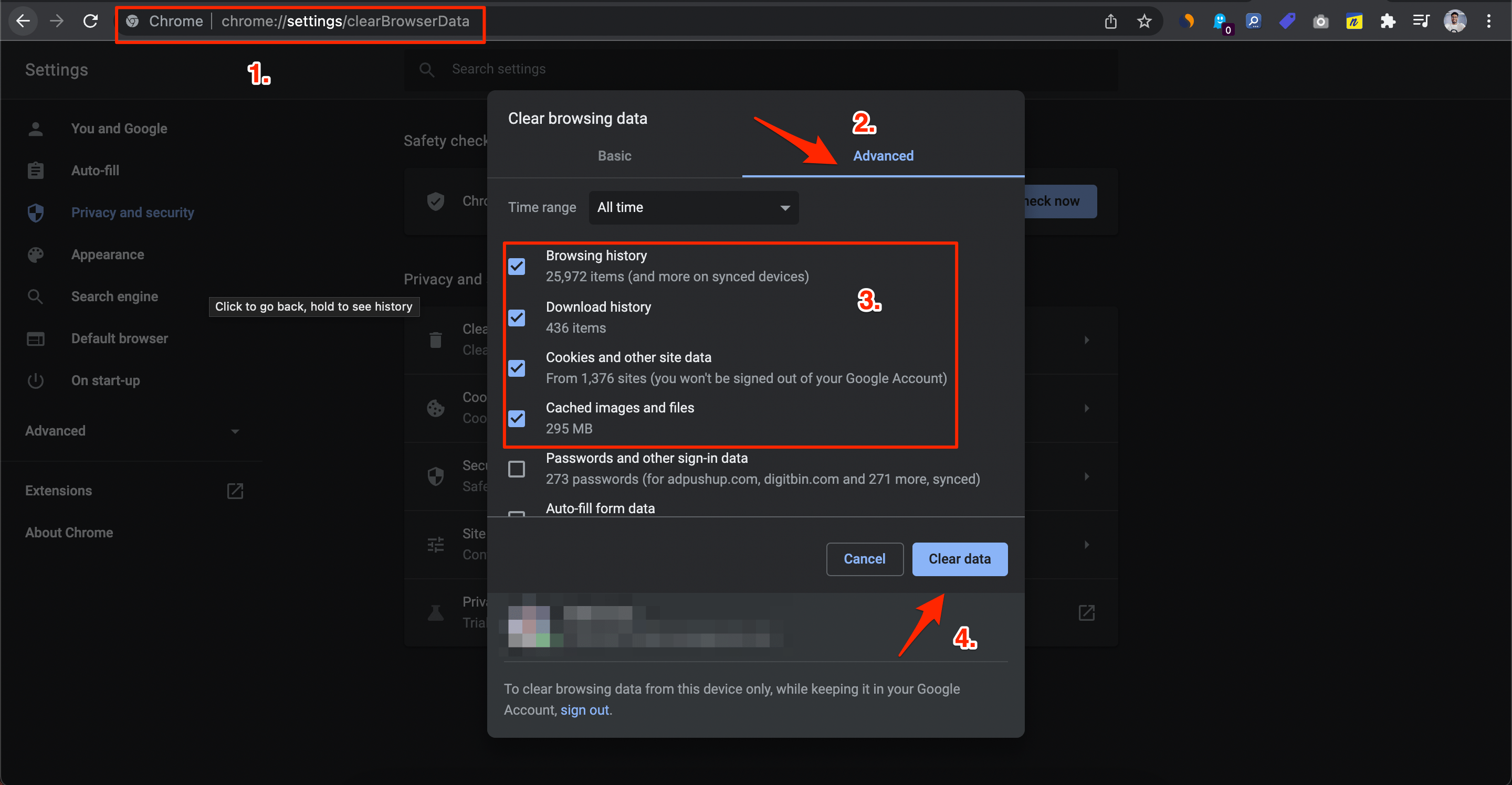
Perché: dati di sessione corrotti o vecchie risposte cache possono bloccare il flusso corretto.
Come fare (esempio con Chrome):
- Apri Impostazioni > Privacy e sicurezza > Cancella dati di navigazione. Seleziona “Cookie e altri dati dei siti” e “Immagini e file memorizzati nella cache”.
- Prova la modalità di navigazione in incognito per vedere se il problema persiste.
Suggerimento: dopo la pulizia, esegui un hard refresh (Ctrl/⌘+Shift+R) per forzare la ricarica completa delle risorse.
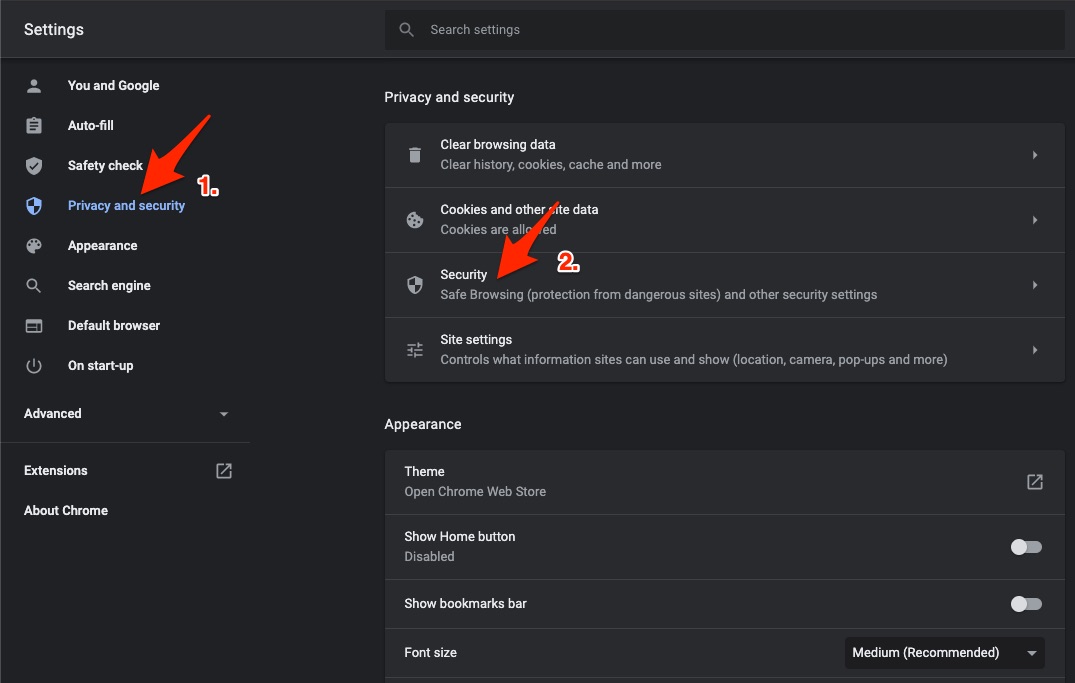
3. Cambia DNS
Perché: un DNS lento o errato fornito dall’ISP può impedire di raggiungere correttamente alcuni endpoint.
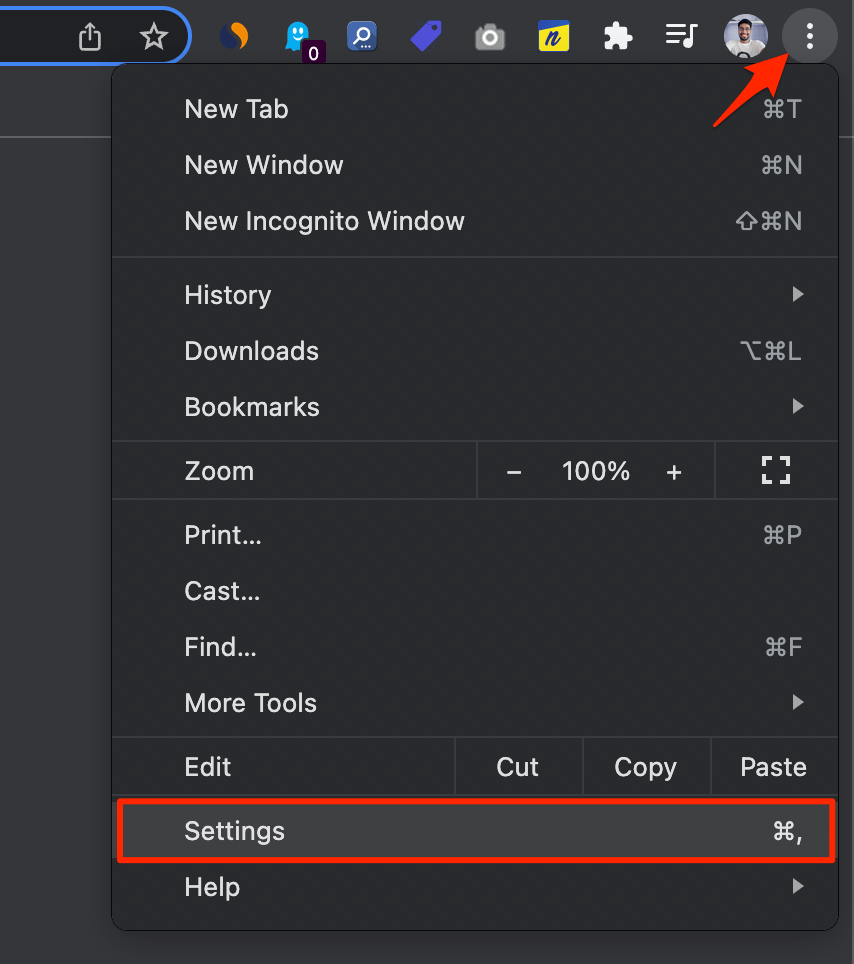
Passaggi (Chrome esempio):
- Apri Impostazioni.
- Vai su Sicurezza e privacy.
- Seleziona Sicurezza.
- Scegli DNS personalizzato e imposta un resolver pubblico (ad es. 1.1.1.1 o 8.8.8.8).
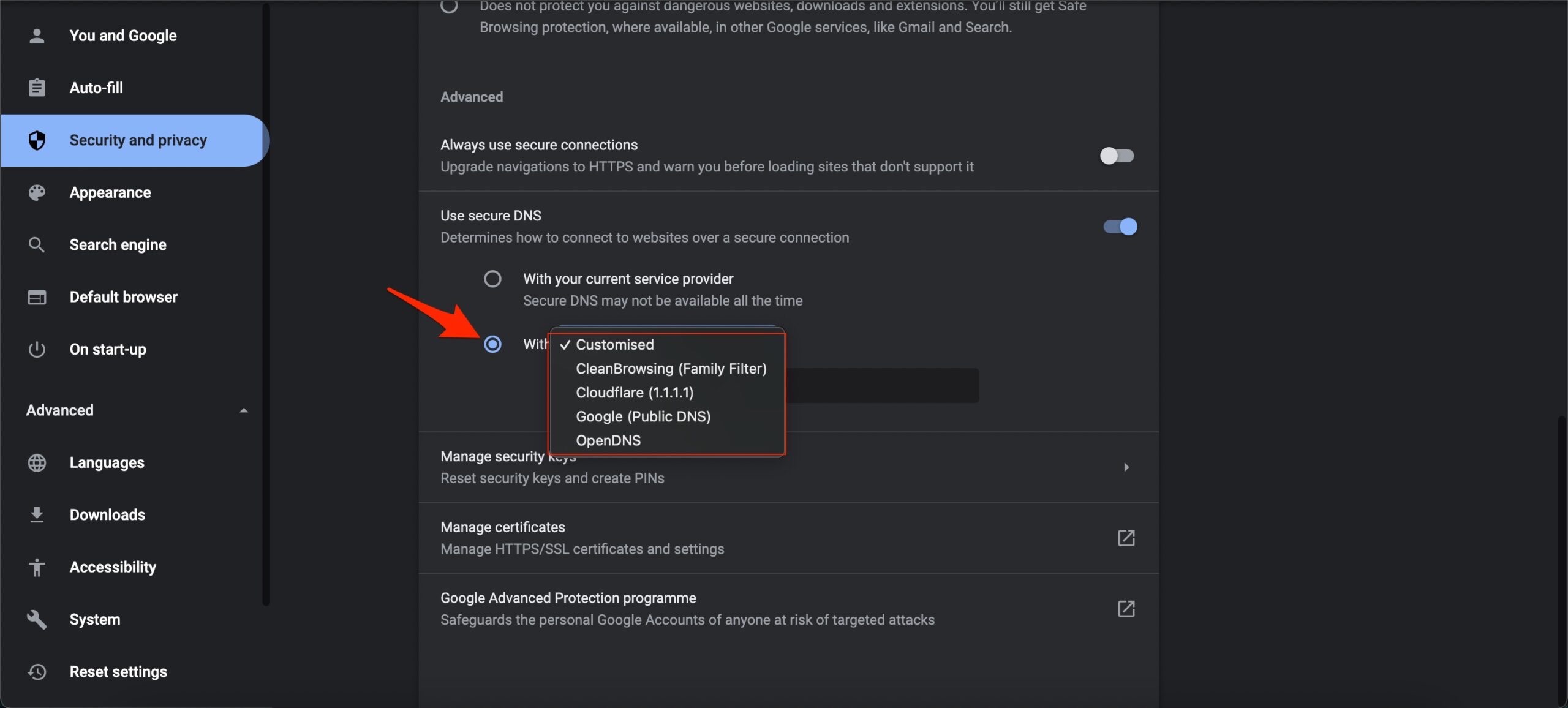
Nota: cambiare DNS non modifica il percorso dati quando il problema è esclusivamente server-side, ma può risolvere problemi di risoluzione degli host.
4. Verifica lo stato dei server
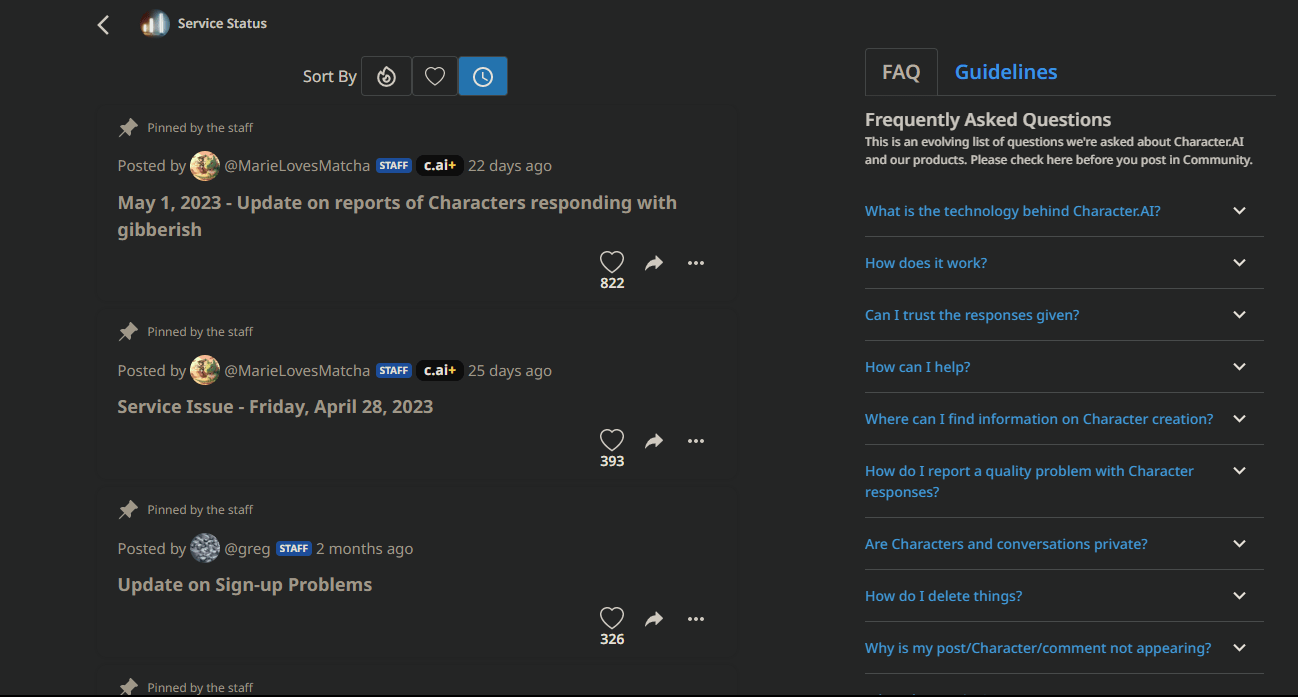
Controlla: la pagina di status ufficiale del servizio (se presente), il feed Twitter/X o la community. Se è un problema segnalato, il team di Character.AI di solito pubblica aggiornamenti e tempi stimati.
Suggerimento: iscriviti agli aggiornamenti di status per ricevere notifiche su riavvii e maintenance.
5. Riavvia browser e router
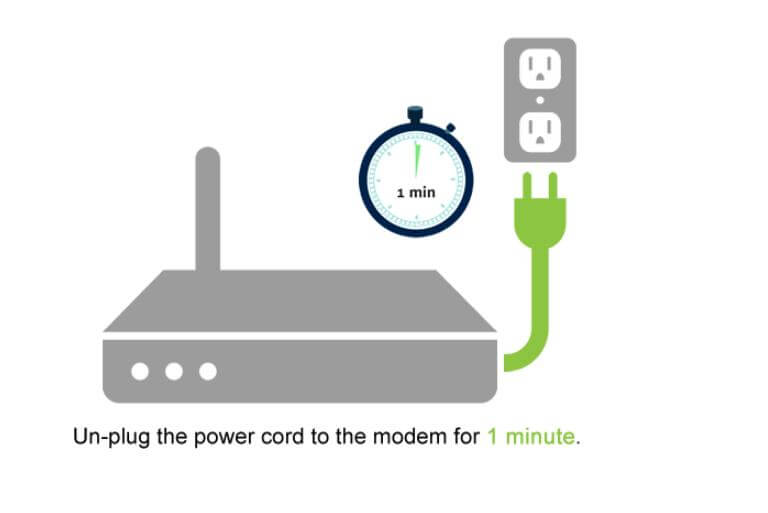
Perché: perdita di pacchetti, cache del router o problemi DHCP possono interrompere la connessione.
Azione: chiudi e riapri il browser, svuota le sessioni, spegni e riaccendi il router. Verifica la connettività con uno speed test o ping su un host affidabile.
6. Contatta il supporto di Character.AI
Se dopo tutti i passi l’errore persiste, contatta il supporto: usa il modulo o l’indirizzo indicato sul sito ufficiale e la sezione Community. Quando scrivi, fornisci:
- Timestamp e URL della richiesta.
- Screenshot dell’errore.
- Output della console del browser (F12 > Console) e degli header della richiesta (Network).
- Eventuali ID di sessione o request ID mostrati dall’app.
Non inventare dati: fornisci solo informazioni reali raccolte localmente.
Diagnostica avanzata per sviluppatori e SRE
Se sei responsabile dell’infrastruttura o stai lavorando in team tecnico, questi passaggi ti aiutano a isolare e risolvere l’incidente.
Raccolta log e first-responder
- Controlla i log dell’applicazione e dei processi (stderr/stdout). Cerca stack trace o eccezioni non gestite.
- Verifica i log del gateway/API proxy (Nginx, Envoy, Cloud Load Balancer) per errori 502/504 correlati.
- Cerca pattern ripetitivi: errori su un endpoint specifico, spike di latenza su dipendenze esterne, errori di autenticazione rate-limiting.
Diagnostica di rete
- Esegui curl o wget dall’infrastruttura verso gli endpoint interni ed esterni.
- Traccia le richieste (tcpdump, Wireshark) se sospetti perdita pacchetti.
- Controlla TTL, aggiornamenti DNS, eventuali firewall o WAF che bloccano richieste.
Esempio rapido: curl -i -v https://api.character.ai/endpoint (sostituisci con endpoint reale) — osserva timeout e header di risposta.
Verifica dipendenze
- DB: controlla connessioni, lock e latenza.
- Cache: esaurimento di risorse su Redis/Memcached può causare errori.
- Servizi esterni: se dipendi da API di terze parti, verifica loro latenza/stato.
Mitigazioni immediate
- Rollback del deploy se l’errore è comparso dopo un rilascio.
- Ridurre il carico (throttling) su endpoint critici.
- Aumentare replica o istanze temporaneamente se il problema è dovuto a picco di traffico.
Runbook d’incidente (SRE) — Flusso minimo operativo
- Detect: alert su 5xx > soglia o aumento error rate.
- Triage: raccogli request IDs, endpoint, minor/major impact.
- Mitigate: applica rate-limiting, disabilita funzionalità non critiche, rollback deploy se correlato.
- Fix: correggi bug o scala le risorse.
- Validate: test end-to-end, smoke test e monitoraggio SLO/SLI.
- Post-mortem: tempo di down, cause radice, azioni preventive.
Criteri di ripristino: error rate < baseline per 30 minuti, latenza nei limiti, no regressioni E2E.
Checklist per i ruoli (veloce)
Utente finale:
- Verifica status e community.
- Cancella cache, prova incognito, cambia DNS, riavvia modem.
- Invia screenshot e console log al supporto.
Operatore/Supporto:
- Raccogli request ID, timestamp, cookie di sessione anonimizzati.
- Conferma se è un problema noto o in corso.
- Guida l’utente su passi semplici prima di aprire ticket interni.
SRE/Dev:
- Controlla deployment recenti.
- Analizza logs, metriche di CPU/memoria, errori DB.
- Applica rollback o mitigation temporanee.
Esempi di test e criteri di accettazione
Test base dopo la correzione:
- Richiesta GET/POST agli endpoint critici restituisce 2xx in X secondi.
- No 5xx ripetuti su 1000 richieste in un periodo di 10 minuti.
- Smoke test dell’app completo: login, chiamata API principale, ricezione risposta corretta.
Criteri di accettazione: error rate per endpoint < 0.5% per 60 minuti; latenza mediana < baseline di produzione.
Nota: evita di inventare soglie specifiche se non sono già definite nel tuo SLO.
Quando un 500 non è davvero un problema del server
- Errore locale del browser (estensioni che modificano response).
- Interferenze di proxy aziendali o VPN che alterano header.
- URL malformato o richieste con payload non previsto dall’API.
Controesempio: se l’errore scompare usando un altro browser o rete mobile, è probabile che il problema sia locale.
Alternative e soluzioni temporanee
- Usa la versione mobile o l’app (se disponibile) come alternativa temporanea.
- Prova accesso da rete dati (4G/5G) per isolare il problema al tuo provider.
- Se necessario per lavoro urgente, usa API mirror o endpoint secondari documentati.
Modello mentale operativo (heuristic)
- Isola: locale vs server vs rete.
- Riduci: limita il dominio del problema (endpoint, client, regione).
- Mitiga: applica fix temporanei che minimizzano l’impatto.
- Risolvi: deploy correttivo e test.
- Previeni: post-mortem e automazioni per evitare recidive.
Matrice dei rischi e mitigazioni (qualitativa)
- Alto rischio — deploy difettoso: mitigazione = rollback immediato, feature flag.
- Medio rischio — dipendenza esterna down: mitigazione = circuit breaker, cached responses.
- Basso rischio — problemi di rete utente: mitigazione = istruzioni per l’utente, fallback client-side.
Glossario (1 riga ciascuno)
- 500: codice HTTP per errore interno del server.
- SRE: Site Reliability Engineering, team che mantiene l’affidabilità del servizio.
- Rollback: ripristino di una versione precedente del software.
- DNS: sistema che risolve nomi di dominio in indirizzi IP.
Suggerimenti di sicurezza e privacy
- Non condividere token o cookie completi quando contatti il supporto: invia solo i dati necessari ed evita informazioni sensibili.
- Quando raccogli log per il supporto, filtra eventuali PII (dati personali identificabili).
Casi limite ed esempi (galleria)
- Errore 500 immediatamente dopo un deploy front-end: spesso rollback risolve.
- 500 solo per alcuni utenti in una regione: controlla bilanciamento e deploy regionale.
- 500 intermittente con spike di latency: indaga su risorse esaurite (DB, connessioni).
Risorse utili
- Console di sviluppo del browser (F12) per vedere Network e Console.
- Strumenti di traccia (curl, tcpdump, traceroute).
- Canali ufficiali di Character.AI: pagina status, sezione Community o support ticket.
Conclusione
L’errore 500 su Character.AI è per lo più un problema lato server, ma la diagnosi corretta richiede un approccio strutturato: verifica rapida da utente, raccolta dei dati, diagnosi tecnica e, se necessario, escalation al supporto con informazioni precise. Seguendo la checklist e il runbook qui riportati, ridurrai i tempi di downtime e migliorerai la qualità delle segnalazioni al team tecnico.
Se hai ulteriori domande su come raccogliere log o vuoi un modello di messaggio da inviare al supporto, scrivi nei commenti. E se segui tutorial video, valuta di iscriverti al canale DigitBin per guide pratiche.
Nota finale: mantieni la calma, raccogli evidenze e comunica in modo chiaro: questo semplifica ogni intervento di supporto.



