Estrarre testo dalle immagini: guida pratica alle tecniche OCR
Che cos’è l’OCR
OCR (Optical Character Recognition) è una tecnologia che trasforma immagini contenenti testo in testo modificabile e ricercabile. Definizione in una riga: OCR analizza i pixel, identifica i caratteri e li converte in testo digitale.
Perché estrarre testo dalle immagini
Le immagini contengono spesso informazioni utili: ricevute, appunti fotografati, screenshot di chat, PDF scansionati. Estrarre il testo rende questi contenuti ricercabili, modificabili e accessibili.
Importante: quando l’immagine contiene dati personali o sensibili, valuta la privacy prima di utilizzare servizi cloud.
Metodo 1 — Usare Gemoo Snap
Gemoo Snap è un’applicazione e un’estensione che integra funzioni di screenshot e OCR. Supporta più lingue, permette l’editing del testo riconosciuto e la copia rapida del risultato.
Caratteristiche principali:
- Riconoscimento testo (OCR) direttamente dall’interfaccia.
- Editing secondario del testo riconosciuto.
- Salvataggio e upload su cloud.
- Estensione Chrome disponibile.
- Codice lingua di output: EN (puoi impostare altre lingue se supportate dall’app).
Passaggi rapidi:
- Scarica e apri Gemoo Snap su Windows o macOS oppure installa l’estensione Chrome.
- Seleziona la funzione Riconosci testo (OCR) dall’interfaccia.
- Imposta il Codice lingua di output su EN (se desideri output in inglese).
- Seleziona l’area dell’immagine da riconoscere.
- Controlla il risultato: usa il pulsante Modifica per correggere errori e il pulsante Copia per salvare il testo.

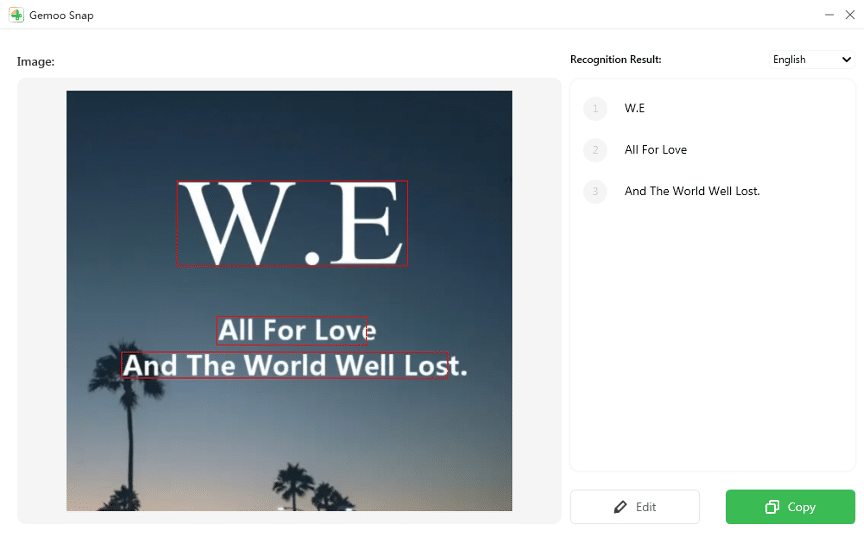
Quando usare Gemoo Snap: per screenshot veloci, estrazione rapida di testo da pagine web, appunti fotografati o immagini sul desktop.
Limiti noti: la qualità del riconoscimento dipende dalla nitidezza dell’immagine, dal contrasto e dalla lingua.
Metodo 2 — Usare Google Drive (Google Docs)
Google Drive/Google Docs integra una funzione OCR semplice e gratuita.
Passaggi:
- Carica l’immagine (JPEG, PNG, PDF) su Google Drive.
- Fai clic destro sul file e scegli Apri con → Google Documenti.
- Google Docs crea un nuovo documento: la pagina superiore conterrà l’immagine e sotto troverai il testo riconosciuto.
- Modifica, formatta e salva come preferisci.
Note pratiche:
- Google Drive è comodo per conversioni veloci e per chi usa già l’ecosistema Google.
- L’accuratezza migliora con immagini nitide e testo orizzontale.
- Alcuni layout complessi (due colonne, tabelle, grafici) possono perdere formattazione.
Metodo 3 — Strumenti OCR online
Esistono servizi web che offrono OCR senza installazione. Alcuni esempi noti: OnlineOCR, Free OCR, OCR.space.
Vantaggi:
- Nessuna installazione.
- Supporto per più formati (JPEG, PNG, PDF, TIFF).
- Possibilità di scegliere la lingua di input.
Svantaggi:
- Limiti di dimensione o numero di file nelle versioni gratuite.
- Potenziali implicazioni sulla privacy (i file vengono caricati su server esterni).
Procedura generica:
- Apri il sito dello strumento OCR.
- Carica l’immagine o il PDF.
- Seleziona la lingua e il formato di output (TXT, DOCX, PDF ricercabile).
- Avvia il riconoscimento e scarica il risultato.
Best practice per migliorare l’accuratezza
- Usa immagini ad alta risoluzione (minimo 300 DPI per documenti stampati).
- Migliora contrasto e luminosità; evita ombre e riflessi.
- Mantieni il testo orizzontale; ruota l’immagine se necessario.
- Preferisci font leggibili; i font decorativi riducono l’accuratezza.
- Per lingue non latine, scegli uno strumento che supporti la lingua specifica.
Suggerimento rapido: se il testo è piccolo, ingrandisci l’area prima del riconoscimento.
Quando l’OCR fallisce: casi ed esempi
Esempi tipici di fallimento:
- Testo scritto a mano molto stilizzato o sovrapposto a texture.
- Immagini mosse o con basso contrasto.
- Layout complessi con elementi grafici vicini al testo.
- Font non standard o simboli speciali non riconosciuti.
Contromisure:
- Preprocessa l’immagine (rimozione rumore, aumento contrasto, binarizzazione).
- Usa servizi di riconoscimento avanzati o modelli dedicati al handwriting.
- Per documenti importanti, combina OCR automatico con una revisione manuale.
Approcci alternativi e avanzati
- API e SDK: servizi come Google Cloud Vision, Microsoft Azure Computer Vision o Tesseract (open source) permettono integrazione programmabile.
- OCR commerciale: offerte enterprise (ABBYY, Adobe Acrobat) offrono migliori risultati su grandi volumi e layout complessi.
- Modelli ML personalizzati: per casi d’uso specifici (es. bollettini, moduli), puoi addestrare modelli di riconoscimento su dataset verticali.
Vantaggio degli SDK/API: automatizzazione e possibilità di pipeline (preprocessamento → OCR → post-elaborazione).
Mini-metodologia: workflow consigliato
- Valuta il volume e la sensibilità dei dati.
- Se è un lavoro saltuario, usa strumenti gratuiti (Google Drive, Gemoo Snap).
- Se hai volumi elevati o requisiti di qualità, scegli API/SDK o soluzioni enterprise.
- Applica preprocessamento (ritaglio, rotazione, miglioramento) prima dell’OCR.
- Automatizza controllo qualità: regole basate su checksum, lunghezza attesa o dizionario.
- Revisiona manualmente i risultati critici.
Checklist per ruolo
Studente / Utente occasionale:
- Scatta foto nitide e ben illuminate.
- Usa Google Drive o Gemoo Snap per conversioni veloci.
- Correggi il testo riconosciuto prima di consegnare.
Professionista / Manager:
- Definisci requisiti di qualità e privacy.
- Scegli uno strumento che supporti il flusso di lavoro (cloud o on-premise).
- Automatizza conversioni ripetute e controlli di qualità.
Sviluppatore / IT:
- Valuta API/SDK adatti (Tesseract per open source, Cloud Vision per scalabilità).
- Implementa preprocessamento (deskew, denoise, binarize).
- Monitora SLI/SLO qualitativi (accuratezza, latenza).
Privacy e note GDPR
- Se l’immagine contiene dati personali, verifica la base giuridica per il trattamento (consenso, necessità contrattuale, obbligo legale).
- Preferisci soluzioni on-premise o EU-based per dati sensibili.
- Anonimizza o minimizza i dati quando possibile prima dell’upload.
Nota: questa sezione non è consulenza legale. Per casi sensibili consulta un legale o il DPO della tua organizzazione.
FAQ — Domande frequenti
Cos’è l’OCR?
OCR significa Optical Character Recognition. È la tecnologia che consente di estrarre testo da immagini e convertirlo in testo modificabile.
Quali sono alcuni software OCR popolari?
Alcuni esempi diffusi sono Gemoo Snap, Adobe Acrobat, ABBYY FineReader e Readiris.
L’OCR può riconoscere la scrittura a mano?
Sì, ma la precisione dipende molto dalla qualità della scrittura. Per scrittura molto scorrevole o irregolare, il tasso di riconoscimento può diminuire.
Da quali formati può estrarre testo l’OCR?
Gli strumenti OCR lavorano con JPEG, PNG, PDF, TIFF e altri formati immagine e PDF.
Quanto è accurato l’OCR?
L’accuratezza varia in base alla qualità dell’immagine, al font, alla lingua e allo strumento. In condizioni buone e con testo stampato e nitido, l’accuratezza può essere molto elevata; in condizioni peggiori è necessaria una revisione manuale.
L’OCR funziona su documenti scannerizzati?
Sì. I documenti scannerizzati sono uno degli usi più comuni dell’OCR.
Esempi di test e criteri di accettazione
Esempi di test da effettuare su uno strumento OCR:
- Test 1: immagine A4, testo stampato, 300 DPI → percentuale di parole riconosciute correttamente (valore qualitativo: soddisfacente/accettabile/insufficiente).
- Test 2: screenshot di chat, font variabile → verifica di punteggiatura e accenti.
- Test 3: documento in lingua non latina → verifica supporto linguistico.
Criteri pratici di accettazione:
- Testo critico (es. dati finanziari): revisione manuale obbligatoria.
- Documenti standard: accuratezza visiva e correzione automatica di errori comuni.
Conclusione
Estrarre parole dalle immagini è oggi semplice grazie a diversi strumenti OCR gratuiti e commerciali. Per lavori occasionali Google Drive o Gemoo Snap offrono una soluzione rapida. Per volumi più elevati o requisiti di qualità, scegli API/SDK o soluzioni enterprise e integra una fase di preprocessamento e revisione. Infine, tieni sempre in conto la privacy dei dati e adotta misure per proteggerli.
Riepilogo:
- Scegli lo strumento giusto in base al volume e alla sensibilità dei dati.
- Migliora le immagini prima dell’OCR per ottenere risultati migliori.
- Automatizza dove possibile, ma revisiona manualmente i contenuti critici.
NOTE: questa guida offre consigli pratici e metodologie; per procedure legali o compliance specifiche contatta un professionista.



