SMART e smartmontools: monitoraggio dei dischi con S.M.A.R.T.
Introduzione
SMART (acronimo di Self-Monitoring, Analysis and Reporting Technology) è una funzionalità integrata nei dischi rigidi e negli SSD che raccoglie attributi statistici e può segnalare anomalie indicative di un possibile guasto. smartmontools è una suite gratuita e multipiattaforma che sfrutta questi attributi per ispezionare lo stato dei dispositivi di storage: fornisce comandi interattivi (smartctl) e un demone di background (smartd) per notifiche automatiche.
Definizione rapida: SMART = insieme di sensori/attributi; smartctl = interazione manuale; smartd = monitoraggio automatico.
Perché usarlo
- Riduce il rischio di perdita dati fornendo avvisi precoci.
- Consente di programmare backup e sostituzioni prima della degradazione critica.
- Integra self-test che possono essere eseguiti in modo pianificato.
Important: SMART non garantisce il rilevamento di tutti i guasti. È un livello aggiuntivo di protezione, ma non sostituisce backup regolari.
Installazione
Su Debian / Ubuntu:
sudo apt-get update
sudo apt-get install smartmontoolsSu Fedora / CentOS (dnf/yum):
sudo dnf install smartmontools
# oppure
sudo yum install smartmontoolsL’installazione fornisce due programmi principali:
- smartctl — uso interattivo/diagnostico
- smartd — demone per monitoraggio continuo e notifiche
Nota: assicurati che il sistema abbia una posta locale funzionante o una procedura di inoltro per ricevere le notifiche inviate da smartd.
Uso di smartctl (diagnosi manuale)
smartctl richiede privilegi di root; usa sudo o esegui come root. smartctl lavora su dispositivi interi (ad es. /dev/sda), non su singole partizioni.
Informazioni generali sul dispositivo:
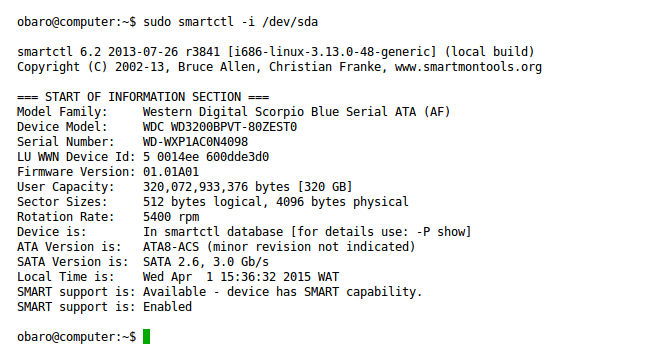
sudo smartctl -i /dev/sda
L’immagine mostra un esempio di output che indica se il supporto SMART è disponibile e attivo. Se SMART è disponibile ma disabilitato, puoi abilitarlo con:
sudo smartctl -s on /dev/sdaVerifica dello stato “health”:
sudo smartctl -H /dev/sda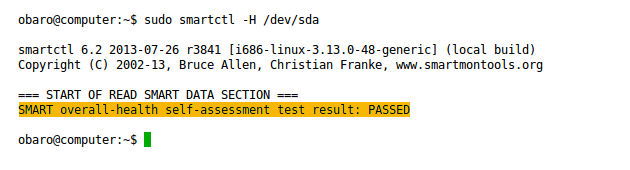
Se l’output non riporta PASSED, considera il disco a rischio: esegui immediatamente backup e pianifica la sostituzione.
Visualizzare le capacità SMART e i self-test disponibili:
sudo smartctl -c /dev/sda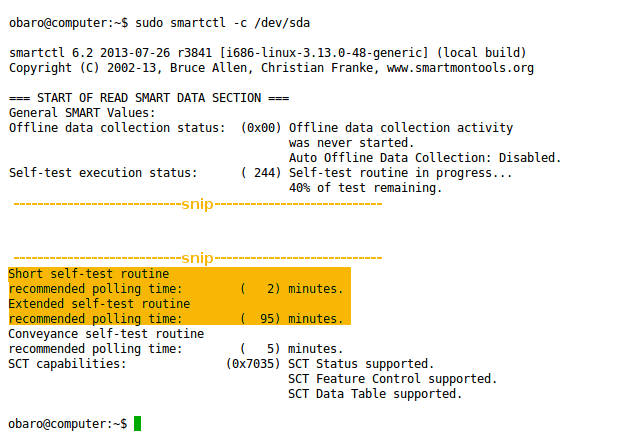
L’output indica se il disco supporta self-test e stima la durata dei test corti e lunghi (ad es. 2 min e 95 min). Per avviare un self-test breve:
sudo smartctl -t short /dev/sda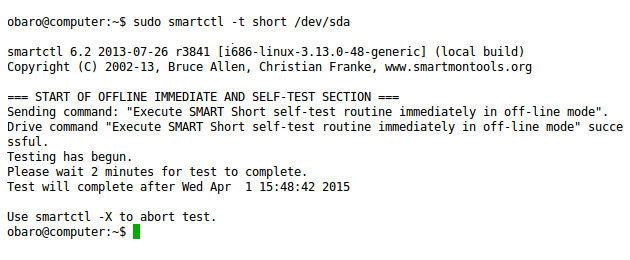
I test vengono eseguiti in background. Per vedere i risultati degli ultimi self-test:
sudo smartctl -l selftest /dev/sdaQuesto comando mostra gli ultimi venti self-test registrati. Per eseguire anche un test esteso (più approfondito):
sudo smartctl -t long /dev/sdaImportant: se un test fallisce, procedi subito al backup e all’analisi approfondita.
smartd: monitoraggio e notifiche automatiche
smartd è il demone che esegue richieste SMART periodiche e invia avvisi quando vengono rilevati errori o fallimenti nei test. La configurazione principale è /etc/smartd.conf.
- Apri /etc/smartd.conf e commenta o rimuovi la direttiva DEVICESCAN se preferisci elencare esplicitamente i dispositivi. Poi aggiungi una riga per ogni disco che vuoi monitorare, ad esempio:
/dev/sda -a -o on -S on -s (S/../.././02|L/../../6/03) -m root -M exec /usr/share/smartmontools/smartd-runnerSpiegazione delle opzioni comuni:
- /dev/sda: file dispositivo del disco
- -a: abilita opzioni comuni (short/long/attributes/error logging)
- -d sat: (opzionale) specifica il tipo di dispositivo; necessario se smartd non lo riconosce
- -o on: abilita i test offline automatici
- -S on: abilita l’autosalvataggio dei parametri SMART
- -s (S/../.././02|L/../../6/03): pianifica i self-test (es. breve ogni giorno alle 02:00, lungo ogni sabato alle 03:00)
- -m root: invia una mail all’utente root (può essere una lista separata da virgole)
- -M exec /usr/share/smartmontools/smartd-runner: esegue uno script helper che può lanciare azioni aggiuntive oltre all’email
Note: se utilizzi controller RAID hardware che presentano dischi via passthrough, potresti dover usare opzioni -d specifiche per il controller.
Per far partire smartd all’avvio:
- Con systemd (sistemi moderni):
sudo systemctl enable --now smartmontools.service- Con init/sysv (vecchi sistemi Debian):
sudo sed -i 's/^#start_smartd=yes/start_smartd=yes/' /etc/default/smartmontools
sudo /etc/init.d/smartmontools startPer testare le notifiche, aggiungi temporaneamente l’opzione -M test sulla riga di /etc/smartd.conf, poi riavvia smartd:
sudo systemctl restart smartmontools.service
# oppure
sudo /etc/init.d/smartmontools restartQuesto invierà una notifica di test alle destinazioni configurate.
Playbook: installazione e messa in produzione (SOP sintetico)
- Installazione pacchetto: apt/yum/dnf.
- Verifica dispositivi disponibili: lsblk, lshw -class disk.
- Controllo manuale iniziale: sudo smartctl -i /dev/sdX ; sudo smartctl -H /dev/sdX.
- Abilita SMART se necessario: sudo smartctl -s on /dev/sdX.
- Avvia un test breve su ogni disco non critico: sudo smartctl -t short /dev/sdX.
- Configura /etc/smartd.conf per i dischi di produzione (usando -a e -m). Verifica l’email locale o configura relay.
- Abilita e avvia il servizio: sudo systemctl enable –now smartmontools.service.
- Monitoraggio: controlla syslog/journal per i messaggi smartd e simula un test di notifica.
- Documenta la politica di azione (quando fare backup, quando sostituire il disco).
Checklist per ruolo
Administrator:
- Installare smartmontools su tutti i nodi rilevanti
- Verificare che SMART sia attivo su ogni disco
- Configurare /etc/smartd.conf con notifiche e self-test
- Assicurare il funzionamento delle email/sistema di alerting
- Automatizzare report settimanali (opzionale)
Operatore / Utente avanzato:
- Eseguire smartctl -H prima di operazioni critiche
- Lanciare smartctl -l selftest per verificare lo storico
- Segnalare tempestivamente qualsiasi avviso all’admin
Quando SMART e smartmontools possono fallire
Counterexample / Limiti:
- SMART non rileva guasti improvvisi come cortocircuiti o danni meccanici istantanei.
- Alcuni SSD o controller esotici possono esporre attributi SMART diversi o incompleti.
- Dischi in array hardware RAID potrebbero non esporre direttamente SMART: il controller deve supportare il passthrough.
Quando dipendere solo da SMART è una cattiva idea: in ambienti HA/mission-critical, mantenere ridondanza e backup invece di affidarsi esclusivamente ad avvisi SMART.
Alternative e integrazioni
- soluzioni di monitoring centralizzate (Prometheus + node_exporter + exporter SMART) per raccogliere metriche storiche
- strumenti commerciali con integrazione ITSM e ticketing
- integrazione con script di orchestration per rimozione automatica da pool di storage
Esempio di flusso decisionale (mermaid)
flowchart TD
A[Avviso SMART ricevuto] --> B{Errore critico?}
B -- Sì --> C[Backup immediato]
C --> D[Sostituzione disco]
B -- No --> E{Compare trend di degrado?}
E -- Sì --> F[Pianifica sostituzione e backup]
E -- No --> G[Monitora più frequentemente]
G --> H[Log e revisione settimanale]Test di accettazione e casi di prova
- Caso 1: dispositivo con SMART disabilitato -> smartctl -i mostra SMART disabled; dopo smartctl -s on, SMART risulta Enabled.
- Caso 2: avvio self-test breve -> smartctl -t short restituisce job id; smartctl -l selftest mostra il risultato quando completato.
- Caso 3: smartd invia mail di test -> impostare -M test e verificare ricezione della mail.
- Caso 4: disco con attributi deteriorati -> smartd invia alert, documento azioni intraprese.
Критерии приёмки
- smartmontools installato su tutti i nodi target
- smartd attivo e abilitato all’avvio
- ricezione di notifiche di test
- playbook e checklist documentati nel sistema di runbook
Suggerimenti pratici e troubleshooting
- Se smartd non parte, controlla i log: sudo journalctl -u smartmontools.service o /var/log/syslog.
- Per controller non riconosciuti, prova diversi parametri -d (es. -d ata, -d sat, -d scsi) con smartctl; riporta lo stesso parametro in smartd.conf.
- Se ricevi falsi positivi, valuta la soglia di intervento: non tutti gli errori SMART richiedono sostituzione immediata.
Breve glossario (1 riga ciascuno)
- SMART: tecnologia di monitoraggio integrata nei dispositivi di storage.
- smartctl: utilità CLI per interrogare e comandare i dispositivi SMART.
- smartd: demone che automatizza il polling e invia notifiche.
- Self-test (short/long): test integrati nel firmware per verificare l’integrità del disco.
Rischi e mitigazioni
- Rischio: avviso mancato per guasto improvviso -> Mitigazione: backup regolari e ridondanza.
- Rischio: mancate notifiche email -> Mitigazione: configurare più canali di alert (slack, webhook, ticketing).
Consigli per il contesto locale (Italia)
- Verifica che il server possa inviare email verso l’esterno (SMTP relay aziendale) e che le policy anti-spam non blocchino le notifiche.
- Documentare la procedura di sostituzione disco in italiano nel runbook operativo e includere riferimenti ai fornitori locali per ricambi rapidi.
Conclusione
SMART e smartmontools forniscono strumenti pratici per ottenere avvisi precoci su problemi di storage, guadagnando tempo prezioso per backup e migrazione dati. Rimangono strumenti complementari: la strategia corretta combina monitoraggio, backup verificati e piani di sostituzione multi-livello.
Note finali:
- Mantieni aggiornato smartmontools e i firmware dei dispositivi quando possibile.
- Integra gli avvisi SMART nel tuo sistema di monitoring centrale per trend e alert coerenti.



