Surveiller la charge système sous Linux avec atop
Important : les exemples ont été testés sur Ubuntu 14.04. Certaines fonctionnalités (comptabilité stockage par processus, relevés réseau par processus) dépendent d’options du noyau ou de patches tels que « cnt ».
Qu’est-ce que atop
atop est, selon sa page de manuel, un moniteur interactif en ligne de commande pour visualiser la charge d’un système Linux. Il présente l’occupation des ressources matérielles (CPU, mémoire, disque, réseau) sous un angle performance, et indique quels processus consomment ces ressources. En plus de l’affichage en temps réel, atop peut enregistrer et rejouer des sessions (utile pour analyse post-incident).
Définition rapide : comptabilité de stockage — mode noyau qui collecte l’I/O par processus ; nécessaire pour afficher la charge disque par PID.
Notes techniques :
- L’affichage de la charge disque par processus requiert que la comptabilité de stockage (storage accounting) soit activée dans le noyau ou que le patch « cnt » soit installé.
- L’affichage de la charge réseau par processus nécessite également le patch « cnt ».
Installation
Sur les distributions basées sur Debian (Ubuntu, Mint, etc.), installez atop avec :
sudo apt-get install atopSur d’autres distributions, utilisez le gestionnaire de paquets natif (par exemple yum / dnf pour Red Hat / CentOS / Fedora). Vous pouvez aussi télécharger les sources ou les binaires depuis le site officiel du projet.
Lancer atop
Pour démarrer l’interface interactive :
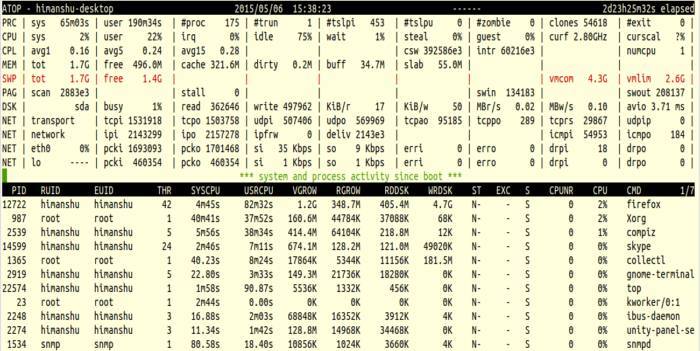
sudo atopExemple d’affichage (écran générique d’atop) :
L’écran est divisé en deux blocs principaux : informations système (niveau global) et informations par processus (niveau PID). L’intervalle par défaut entre deux mises à jour est de 10 secondes ; il peut être ajusté lors du lancement.
Interprétation des lignes système
Voici les lignes système les plus utiles et leur interprétation synthétique :
PRC — statistiques globales de processus : temps CPU en mode noyau (
sys) et utilisateur (user), nombre total de processus (#proc), threads enrunning, ensleepinginterruptibles et non-interruptibles, zombies, clones, et processus terminés pendant l’intervalle (#exit) si la comptabilité des processus est active.CPU — pourcentage du temps CPU :
sys(noyau),user(espace utilisateur),irq(interrupts matériels et softirq),idle(inactif sans attente I/O),wait(attente d’I/O disque). Sur systèmes multi-cœurs, une ligne par CPU physique peut apparaître.CPL — charge du CPU / file d’attente : nombre de threads prêts à tourner (runqueue) ou en attente I/O, nombre de commutations de contexte (
csw), interruptions traitées (intr) et nombre de CPUs disponibles.MEM — mémoire physique : total (
tot), libre (free), page cache (cache), pages sales à écrire (dirty), tampons (buff) et mémoire noyau type slab (slab).SWP — swap : total (
tot), libre (free), mémoire virtuelle engagée (vmcom) et limite de l’engagement (vmlim).DSK — disque : pourcentage du temps occupé à servir des requêtes (
busy), nombre de lectures/écritures, Ko par lecture/écriture (KiB/r,KiB/w), débit en MiB/s (MBr/s,MBw/s), profondeur moyenne de file d’attente (avq) et latence moyenne par requête (avio).NET — réseau (pile TCP/IP) : lignes pour transport (TCP/UDP), IP, et une ligne par interface active (octets/sec, paquets, erreurs).
Atop utilise des couleurs (rouge, cyan, etc.) pour alerter sur des consommations critiques ; par exemple, une ligne en rouge signifie que l’occupation a dépassé un seuil critique.
Note : consultez la page de manuel (
man atop) pour la liste complète des champs et leurs significations.
Commandes interactives et affichages utiles
Dans l’interface, vous pouvez appuyer sur des touches pour filtrer ou enrichir l’affichage :
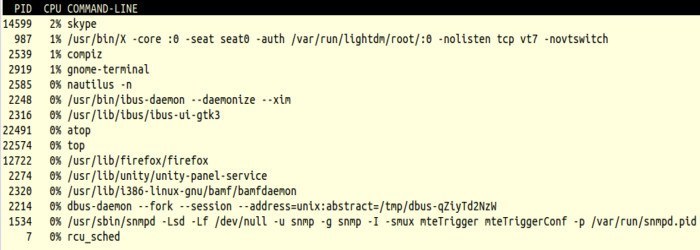
m— afficher uniquement les données mémoired— afficher les statistiques disquen— afficher les statistiques réseauv— afficher diverses caractéristiques des processusc— afficher la ligne de commande des processus (utile pour identifier les services)
Voici un exemple d’affichage niveau processus après avoir appuyé sur c :
Commandes non interactives (enregistrement et lecture)
Atop peut enregistrer les données en arrière-plan et les rejouer ultérieurement :
- Pour écrire un journal binaire :
sudo atop -w /var/log/atop.log 60 100(exemple : écriture toutes les 60 secondes pendant 100 échantillons)
- Pour lire un fichier journal :
sudo atop -r /var/log/atop.logCela permet d’analyser une période où un incident a eu lieu sans être présent au moment exact.
Fiche pratique — Cheat sheet rapide
- Lancer :
sudo atop - Installer :
sudo apt-get install atop - Activer l’enregistrement :
sudo atop -w /chemin/fichier 60 - Lire un enregistrement :
sudo atop -r /chemin/fichier - Touches courantes :
m,d,n,v,c,h(aide) - Interpréter : cherchez les lignes « DSK » / « MEM » / « CPU » en rouge puis remontez vers le PID responsable.
Mini-méthodologie : utiliser atop dans vos procédures de surveillance
- Baseline : enregistrez 24–72 h en conditions normales (ex.
atop -w baseline.atop 300 576) pour obtenir des valeurs de référence. (300 = 5 min, 576 échantillons = 48 h) - Détection : lancez atop en mode interactif pour diagnostiquer en temps réel un symptôme.
- Enregistrement ciblé : lors d’une opération risquée (mise à jour, migration), activez l’enregistrement pour conserver la trace.
- Analyse : utilisez
atop -rpour relire et filtrer les périodes problématiques. Croisez avec logs applicatifs. - Automatisation : intégrez la rotation des logs atop avec logrotate et des scripts d’archivage.
Important : ne confiez pas la rétention longue durée à des fichiers atop bruts ; si vous avez besoin d’indexation et d’alerting, exportez vers un système de métriques (Prometheus, InfluxDB) ou transformez les logs dans un format adapté.
Scénarios de dépannage — Diagnostic rapide
Symptôme : latence disque élevée
- Vérifier
DSK:busy,avio,avq; si occupé > 80% etavioélevé, explorer PIDs causants. - Passer en
det noter quels PIDs effectuent le plus d’I/O. - Solutions possibles : déporter I/O, optimiser requêtes, vérifier saturation RAID/contrôleur.
- Vérifier
Symptôme : CPU saturé
- Vérifier
CPUetCPLpour pressions dans la runqueue. - Repérer PIDs en tête via la section processus ; noter la commande (
c). - Si beaucoup de processus en
D(uninterruptible sleep), problème I/O lié.
- Vérifier
Symptôme : fuite mémoire / OOM
- Vérifier
MEMetSWP: usage croissant detotet swap accru. - Identifier processus avec forte
RESetVMdans la liste des processus. - Redémarrer le service incriminé ou ajuster limites si confirmé.
- Vérifier
Contre-exemples et limites d’atop
- atop n’est pas conçu comme base de données temporelle longue durée (ex. retenue et requêtes analytiques historiques complexes). Pour cela, préférez une solution TSDB.
- Les vues par processus pour disque/réseau peuvent être incomplètes si le noyau ne fournit pas la comptabilité nécessaire.
- Dans des environnements conteneurisés, adaptez : certains champs peuvent refléter l’hôte plutôt que le conteneur selon la manière dont les cgroups et le noyau exposent les métriques.
Checklist par rôle
Sysadmin :
- Installer et vérifier la présence de
atopsur les serveurs critiques - Activer l’enregistrement temporaire avant une maintenance
- Intégrer la rotation des fichiers atop dans logrotate
- Installer et vérifier la présence de
DevOps / SRE :
- Ajouter atop à la boîte à outils d’investigation post-incident
- Documenter les seuils locaux (ex. DSK busy > 75%) pour alerting
- Corréler avec métriques applicatives et traces distribuéess
Support / Helpdesk :
- Savoir exécuter
sudo atopet prendre une capture d’écran - Remonter les PIDs avec leur commande au niveau d’ingénierie
- Savoir exécuter
Critères d’acceptation
- atop est installé et démarre sans erreur (
sudo atopaffiche l’écran principal) - L’enregistrement fonctionne (
sudo atop -w /var/log/atop.log 60 12) et le fichier est lisible (sudo atop -r /var/log/atop.log) - Les équipes peuvent identifier un PID coupable en moins de 5 minutes lors d’un incident type CPU/IO/mémoire
Compatibilité et conseils de migration
- Distributions : Debian/Ubuntu, Red Hat/CentOS/Fedora — installez via le gestionnaire natif. Pour systèmes non packagés, compiler depuis les sources est une option.
- Noyau : vérifiez si la comptabilité par processus pour disque/réseau est activée. Sans cela, certains détails par PID ne seront pas disponibles.
- Conteneurs : pour obtenir des métriques pertinentes par conteneur, assurez-vous que les cgroups exposent les compteurs nécessaires et testez l’affichage sur des nœuds hôtes.
Bonnes pratiques de sécurité et confidentialité
- Protégez les fichiers journaux atop : ils contiennent des lignes de commande de processus (parfois avec arguments sensibles). Restreignez la lecture à des comptes d’administration.
- Ne conservez pas indéfiniment les logs binaires sans chiffrement si des données sensibles peuvent apparaître.
Résumé
Atop est un outil puissant pour diagnostiquer la charge système en temps réel et pour enregistrer des sessions quand un incident doit être analysé après coup. Il n’a pas vocation à remplacer une plateforme de monitoring historique, mais il excelle pour l’investigation et la corrélation processus→ressource.
Points clés :
- Installez atop via votre gestionnaire de paquets et testez
sudo atop. - Utilisez les touches interactives (
m,d,n,c) pour focaliser les diagnostics. - Activez l’enregistrement (
-w) avant opérations à risque, et relisez avec-r. - Intégrez atop dans vos playbooks d’incident, mais combinez-le avec une solution TSDB pour l’historique longue durée.
Appel à l’action : essayez d’enregistrer 24 heures de charge normale pour établir une baseline, puis relisez-la afin d’apprendre à distinguer comportement normal et anomalies.
Matériaux similaires

Installer et utiliser Podman sur Debian 11
Guide pratique : apt-pinning sur Debian

OptiScaler : activer FSR 4 dans n'importe quel jeu
Dansguardian + Squid NTLM sur Debian Etch

Corriger l'erreur d'installation Android sur SD
