Surveillance Linux sur Ubuntu — GNOME, top/htop et lm-sensors
Ce guide explique comment installer et utiliser GNOME System Monitor, top/htop et lm-sensors sur Ubuntu pour superviser CPU, RAM, disque, réseau et températures. Inclut une feuille de commandes, une méthode de dépannage, des alternatives pour la surveillance à distance et des checklists rôle par rôle.
Pourquoi surveiller un système Linux
Surveiller votre système Linux est essentiel pour améliorer ses performances, identifier l’origine d’un problème et prendre des actions correctives ciblées. Linux offre de nombreux outils. Ici, nous présentons trois outils simples à installer et à utiliser sur Ubuntu, puis nous proposons des conseils pratiques pour aller plus loin.
GNOME System Monitor
GNOME System Monitor fournit une vue graphique des ressources système. Il montre la charge CPU, l’utilisation de la RAM, l’espace d’échange (swap), la taille et l’espace disque disponible, ainsi que l’activité réseau (envoyé/reçu).
Installez-le depuis le gestionnaire de paquets ou avec cette commande :
sudo apt-get install gnome-system-monitor
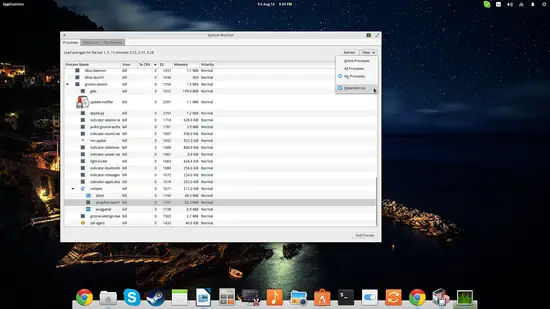
La première onglet est dédié à la gestion des processus. Vous pouvez trier les processus par usage mémoire ou charge CPU et cliquer sur « End Process » pour terminer un processus sélectionné. Activez « Dependencies » dans le menu « View » pour afficher les processus enfants dans une vue en arbre.
Le deuxième onglet affiche l’historique d’utilisation du CPU (par cœur), de la RAM, du swap et l’activité réseau. C’est utile pour repérer une action qui dégrade les performances. Notez que les préférences n’offrent pas d’option pour augmenter la fenêtre historique affichée.
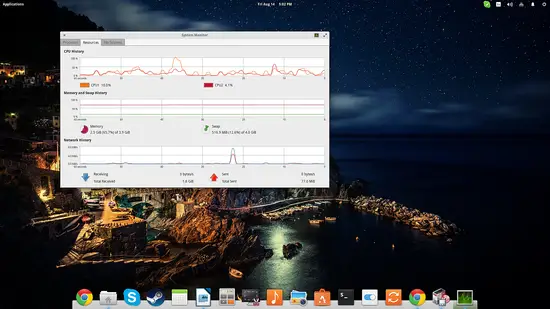
Important: GNOME System Monitor est pratique pour une surveillance ponctuelle en local. Pour une surveillance continue ou centralisée, préférez des solutions dédiées (voir alternatives ci-dessous).
Top et htop
Top est un moniteur en ligne de commande. Il affiche en temps réel les processus et leur consommation.
topDans top, appuyez sur “P” pour trier par utilisation CPU, ou sur “M” pour trier par mémoire.
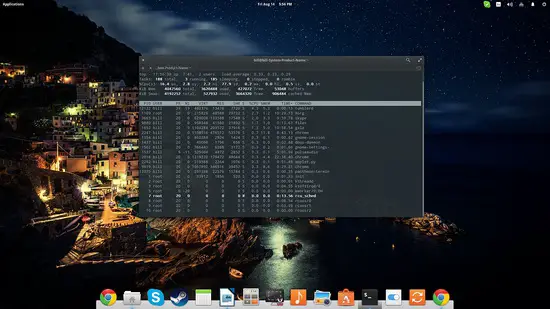
Htop est une version améliorée, plus ergonomique et interactive. Installez-le et lancez-le :
sudo apt-get install htophtopHtop facilite le tri, la recherche et la terminaison de processus. Utilisez les touches F1–F10 pour accéder aux options. Htop propose aussi une vue en arbre, des barres de charge colorées et des actions rapides.
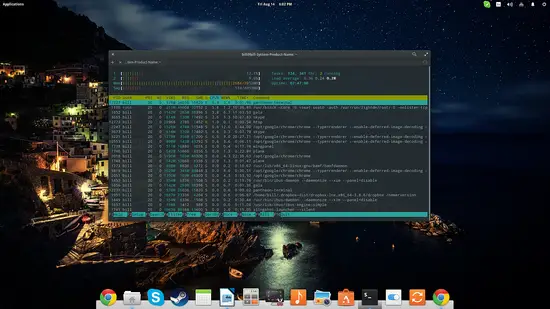
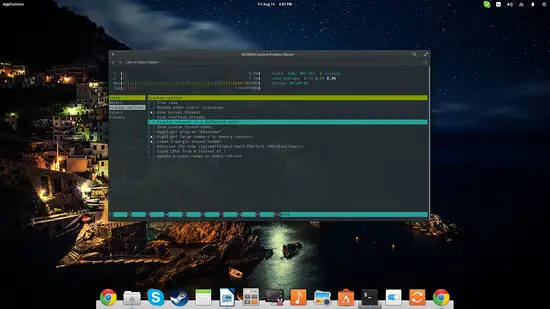
Astuces rapides:
- Dans htop, F6 permet de changer la colonne de tri.
- F9 (Kill) envoie un signal au processus sélectionné.
- Maj+M trie rapidement par mémoire.
Lm-sensors
Lm-sensors surveille les températures et tensions du matériel. C’est utile pour détecter une surchauffe ou une anomalie électrique.
sudo apt-get install lm-sensorsAprès installation, détectez les capteurs disponibles (parfois sudo required pour sensors-detect) puis lancez :
sensors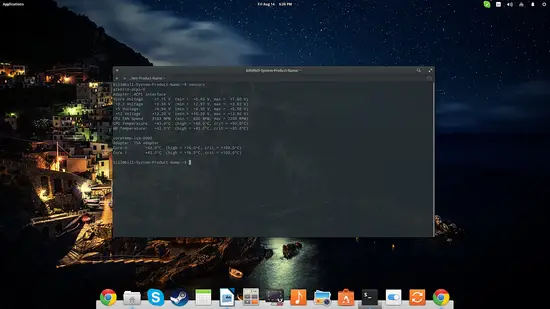
Pour une interface graphique et un accès à distance, explorez le paquet psensors.
Feuille de commandes (cheat sheet)
Commandes essentielles :
- sudo apt-get install gnome-system-monitor — installer GNOME System Monitor
- gnome-system-monitor — lancer l’interface graphique
- top — moniteur CLI simple
- sudo apt-get install htop && htop — installer et lancer htop
- sudo apt-get install lm-sensors && sensors — installer et lire les capteurs matériels
- free -h — voir la mémoire libre et utilisée en format lisible
- df -h — afficher l’espace disque utilisé
- iostat -x 1 — statistiques d’E/S disque (package sysstat)
- ss -tuna — état des connexions réseau
Fact box — commandes à retenir :
- Surveillance CPU/mémoire: htop, top, free -h
- Disque: df -h, du -sh
- Températures: sensors
- Réseau: ss, iftop (surveillance en temps réel)
Mini-méthodologie de dépannage
- Observer: collectez métriques (CPU, RAM, disque, réseau, températures).
- Corréler: notez l’heure et comparez les historiques.
- Isoler: identifiez le processus ou le service en cause.
- Tester: redémarrez le service ou limitez la charge.
- Corriger: appliquez la solution (patch, configuration, limitation de ressource).
- Valider: surveillez après correctif pour confirmer la résolution.
Conseil: capturez des logs et des sorties (top, htop, dmesg, journalctl) avant d’agir.
Quand ces outils sont insuffisants
Ces outils sont excellents pour une vérification manuelle et locale. Ils montrent leurs limites pour:
- Surveillance continue à grande échelle
- Collecte historique longue durée
- Alertes et tableaux de bord centralisés
Alternatives et approches pour production :
- Netdata, Prometheus + Grafana pour métriques et dashboards
- Zabbix, Nagios pour supervision et alerting
- Elastic Stack (Elasticsearch, Logstash, Kibana) pour logs et corrélation
- Atop, sar (sysstat) pour historique détaillé d’usage
Sécurité et confidentialité:
- Chiffrez les communications entre agents et serveurs.
- Filtrez les métriques sensibles si vous envoyez des données à un tiers.
- Limitez l’accès aux dashboards via authentification forte.
Checklists par rôle
Administrateur système:
- Installer htop, lm-sensors, sysstat
- Mettre en place sauvegardes et alertes
- Centraliser les métriques (Prometheus/Grafana)
Développeur:
- Reproduire la charge localement avec stress/nginx ab
- Utiliser htop pour identifier fuites mémoire
- Collecter traces et logs (journalctl)
Support / Helpdesk:
- Demander captures htop/top et sensors
- Vérifier utilisation disque et fichiers logs
- Escalader avec timestamps et actions déjà effectuées
Diagramme de décision
flowchart TD
A[Problème de performance] --> B{Impact local ou global?}
B -->|Local| C[Utiliser top/htop + sensors]
B -->|Global| D[Consulter Prometheus/Grafana]
C --> E[Isoler processus]
D --> F[Examiner dashboards & alertes]
E --> G[Appliquer correction & monitorer]
F --> GNotes:
- Sauvegardez toujours les logs avant une action corrective invasive.
- Pour serveurs distants, évitez d’exposer les interfaces graphiques sans tunnel sécurisé.
Résumé
- GNOME System Monitor est pratique en local pour une vue graphique rapide.
- top et htop sont indispensables en ligne de commande pour diagnostiquer les processus.
- lm-sensors rapporte températures et tensions matérielles.
- Pour une supervision continue ou à distance, choisissez des solutions centralisées (Prometheus, Netdata, Zabbix).
Principales actions recommandées:
- Installez htop et lm-sensors pour commencer.
- Utilisez la mini-méthodologie d’observation -> isolation -> correction.
- Centralisez les métriques pour la production et mettez en place des alertes.
Important: avant toute modification critique sur un serveur en production, planifiez une fenêtre de maintenance et informez les parties prenantes.
Matériaux similaires

Installer et utiliser Podman sur Debian 11
Guide pratique : apt-pinning sur Debian

OptiScaler : activer FSR 4 dans n'importe quel jeu
Dansguardian + Squid NTLM sur Debian Etch

Corriger l'erreur d'installation Android sur SD
